



1.文件对象 1.打开文件 open open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None,
1.文件对象
1.打开文件

open
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
mode
mode决定了open的返回值
mode决定了所返回的文件对象的特性
当mode为b的时候,返回的文件对象是以字节为单位操作操作文件的
当mode为t的时候,返回的文件对象是以字符为单位操作文件的,这是默认模式
文件对象维持一个指针,指向当前所操作的位置。下一次操作,会从这个位置开始
mode决定了open的返回值
mode决定了所返回的文件对象的特性
- b t
当mode为b的时候,返回的文件对象是以字节为单位操作操作文件的(未解码)
当mode为t的时候,返回的文件对象是以字符为单位操作文件的(已解码),这是默认模式
- r w a
mode为w时总是清空文件,修改mtime,未修改ctime,区别于删除源文件
mode为r时,打开的文件可读,不可写,默认行为
mode为w时,打开的文件可写
mode为a时,打开的文件可追加内容
读写追加只能是其中一种
- +
mode为r+时,打开的文件可读可追加 文件指针在开头,任意位置插入覆盖
, mode为w+时,打开的文件可读可写
mode为a+时,打开的文件可读可追加 文件指针在结尾,固定追加末尾
- x w
当文件不存在时,x和w会创建文件 但是当文件存在时,x会抛出FileExistsError
凡是有r的,都不会创建文件,当文件不存在时,报FileNotFoundError
buffering
默认-1为默认缓冲区大小
【w二进制模式】
buffering设置为0时,关闭缓冲区

write操作时,会先计算缓冲区剩余能否写入不溢出,溢出会先flush缓冲区到硬盘再写入缓冲区
【t文本模式】
缓冲区为默认大小,buffering设置只是改变模式
buffering不能设置为0
buffering设置为1时,会根据换行符/n刷新缓冲区,写入溢出,会flush缓冲区到硬盘再写入硬盘
buffering设置为其他时,无效,等同于默认,写入溢出,会flush缓冲区到硬盘再写入硬盘
encording
只在文本模式下生效
默认编码是utf-8
编码不同会报UnicodeDecodeError
errors
ignore 忽略编码错误
strict 默认模式,不忽略编码错误
2.读 f.read(size=-1)



3.写 f.read(size=-1)
写操作的时候,换行符始终需要显示传入
write 和 writelines的区别: write参数为字符串/bytes;writelines参数时一个可迭代对象,且元素会字符串/bytes
writelines会遍历参数,然后写入
write 返回写入的字符数/字节数,writelines返回None
write 操作总是向后移动文件指针
- 当mode为写模式的时候,从当前文件指针指向开始写入,往后覆盖
- 当mode为追加模式的时候,write操作总是从文件结尾处操作
当mode包含a的时候,总是从文件末尾开始写,否则总是从文件指针位置开始写
4.清空 f.truncate(pos=None)

truncate操作,如果不指定位置,从当前文件指针位置开始清空;如果指定位置,从指定位置开始
5.关闭 f.close()
打开的文件会占用文件描述符,达到上限会无法打开新文件,一定要关闭
with open('hello.py') as fd: fd.read()context上下文管理(域内),可以帮助我们自动关闭文件,无论发生什么(异常,return)
6.缓冲区 f.flush()

7.移动文件指针 f.seek(cookie, whence=0)

seek用于移动文件指针
whence 0 从开始处移动, 1 从当前位置移动, 2 从文件末尾位置移动
offset 为正数,向后移动,为负数向前移动
seek移动数是字节数
当文本模式打开,whence只能是0
seek不可以移动到文件头之前
seek可以移动到文件末尾之后
当seek到文件末尾之后,操作是从文件开始处开始
2.目录对象
1.创建 os.mkdir(path, mode=511, *, dir_fd=None)
os.mkdir('/tmp/test') # 创建目录os.makedirs('/tmp/test2/test3')#递归创建目录,相当于mkdir -p os.mkdir 不能递归的创建目录
os.makedirs 可以递归的创建目录
当目录存在时,mkdir和makedirs都会抛出异常
os.makedirs(name, mode=511, exist_ok=False)
os.makedirs('/tmp/test2/test3', exist_ok=True)#设置True,目录存在不抛出异常
2.删除 os.rmdir(path, *, dir_fd=None)
os.rmdir('/tmp/test')#只能删除空目录os.removedirs('/tmp/test2/test3') #只能递归删除空目录import shutilshutil.rmtree('/tmp/test2') #删除空目录shutil.rmtree 递归删除目录,要考虑权限
shutil.rmtree(path, ignore_errors=False, onerror=None)
ignore_errors=False设置为True可忽略错误,即使没有删除成功
onerror=None设置为lambd fn, path exc_info: print(path)输出删除不成功路径
3.移动 shutil.move(src, dst, copy_function)
shutil.move('/tmp/test/test.txt', '/tmp/test2')4.复制 shutil.copy(src, dst, *, follow_symlinks=True)
copy 数据与权限
copy2 数据与stat info(权限、atime,ctime,mtimie,flage)
copyfile 数据
copymode 权限
copystat stat info
copytree 递归复制目录
shutil.copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2)
shutil.copytree('/tmp/test/test.txt', '/tmp/test2', symlinks=True) # 连接文件也复制,软连接,没开启,硬连接5.遍历目录 os.lstdir(path=None)
import osos.lstdir() # 默认当前目录广度优先
def listdir(path=None): if path is None: path = '.' dirs = [path] files = [] while dirs: path = dirs.pop() for f in os.listdir(path): if os.path.isdir(f): dirs.append(os.path.join(path, f)) else: files.append(os.path.join(path, f)) return files标准库里的遍历
os.walk(top, topdown=True, onerror=None, followlinks=False)
import osos.walk()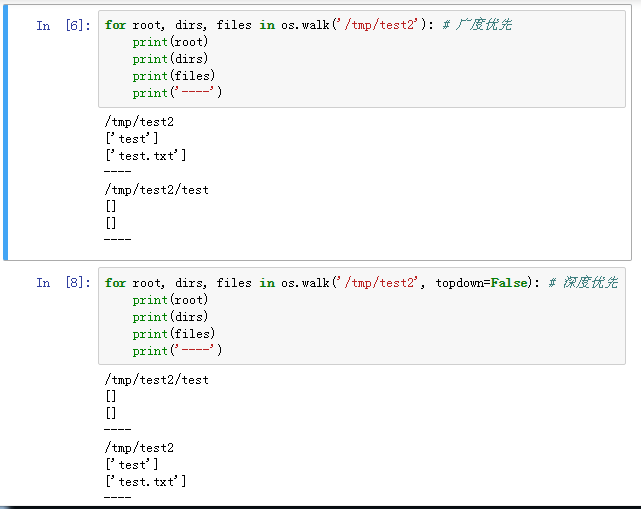
其他

路径相关
os.path.basename('/tmp/test2/test.txt') # basename'test.txt'os.path.dirname('/tmp/test2/test.txt') # dirname'/tmp/test2'os.path.join('/', 'tmp', 'd', 'a') # 自动识别文件系统'/tmp/d/a'os.path.split('/tmp/test2/test.txt') # (dirname, basename)('/tmp/test2', 'test.txt')os.path.abspath('./test.txt') # 相对路径返回绝对路径'/home/Lock/python3_study/test.txt'os.path.abspath('../test.txt')'/home/Lock/test.txt'os.path.abspath('../test/.../test.txt')'/home/Lock/test/.../test.txt'import sys # 脚本名print(sys.argv)['/home/Lock/.pyenv/versions/3.5.2/envs/Lock/lib/python3.5/site-packages/ipykernel/__main__.py', '-f', '/run/user/1000/jupyter/kernel-011acde7-617d-406b-82fc-953cf942db7d.json']os.path.abspath(os.path.dirname(sys.argv[0])) # 获取脚本绝对路径os.getcwd()'/home/Lock/python3_study'os.path.splitext('test.txt')('test', '.txt')3.序列化与反序列化
pickle
序列化 对象 -> str/bytes
反序列化 str/bytes -> 对象
序列化
import picklepickle.dumps(1) # 序列化 数字b'/x80/x03K/x01.'pickle.dumps([1, 2, 3]) # 序列化 列表b'/x80/x03]q/x00(K/x01K/x02K/x03e.'pickle.dumps({'a':1}) # 序列化 字典b'/x80/x03}q/x00X/x01/x00/x00/x00aq/x01K/x01s.'pickle.dumps(a) # 序列化 类b'/x80/x03c__main__/nA/nq/x00)/x81q/x01}q/x02X/x01/x00/x00/x00aq/x03K/x03sb.'import osfp = io.BytesIO()pickle.dump(a, fp)# fp是一个类文件对象fp.read()b'/x80/x03c__main__/nA/nq/x00)/x81q/x01}q/x02X/x01/x00/x00/x00aq/x03K/x03sb.'反序列化
b = pickle.load(fp)b<__main__.A at 0x7f42985d3748>a<__main__.A at 0x7f42985bceb8>b.print()3pickle的序列化与反序列化,能针对大多数的python对象,包括他们的方法
pickle是python特有的,只能在python之间传递数据使用
json
import jsonjson.dumps(1)'1'json仅仅可以序列化内置类型(除集合)
int float list tuple string bool None
py json
int --> number
float --> number
str --> string
bool --> bool
None --> null
list --> Array
tuple --> Array
dict --> object
4.其他类文件对象
socket
在服务端:

在客户端:

sock.close()在服务端:

