



先上代码 BaseSpider.java: importjava.io.BufferedReader;importjava.io.IOException;importjava.io.InputStre
先上代码
BaseSpider.java:
import java.io.BufferedReader;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import org.apache.commons.httpclient.Cookie;import org.apache.commons.httpclient.HttpClient;import org.apache.commons.httpclient.HttpException;import org.apache.commons.httpclient.HttpMethod;import org.apache.commons.httpclient.NameValuePair;import org.apache.commons.httpclient.URIException;import org.apache.commons.httpclient.cookie.CookiePolicy;import org.apache.commons.httpclient.methods.GetMethod;import org.apache.commons.httpclient.methods.PostMethod;import org.apache.commons.httpclient.params.HttpMethodParams;import org.apache.commons.httpclient.protocol.Protocol;import org.apache.commons.httpclient.protocol.ProtocolSocketFactory;public class BasicSpider { public HttpClient client = null; protected String lastUrl; private String ENCODING="UTF-8"; public String getENCODING() { return ENCODING; } public void setENCODING(String eNCODING) { ENCODING = eNCODING; } public HttpClient getClient() { return client; } public void setClient(HttpClient client) { this.client = client; } public void setHeaders(HttpMethod method) { method.setRequestHeader("Accept", "text/html,application/xhtml+xml,application/xml;"); method.setRequestHeader("Accept-Language", "zh-cn"); method .setRequestHeader( "User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3"); method.setRequestHeader("Accept-Charset", "UTF-8"); method.setRequestHeader("Keep-Alive", "300"); method.setRequestHeader("Connection", "Keep-Alive"); method.setRequestHeader("Cache-Control", "no-cache"); } public String doPost(String actionUrl, NameValuePair[] params, String referer, String encoding) throws HttpException, IOException { PostMethod method = new PostMethod(actionUrl); setHeaders(method); method.setRequestHeader("Referer", referer); method.setRequestHeader("Content-Type", "application/x-www-form-urlencoded"); method.setRequestBody(params); client.getParams().setCookiePolicy(CookiePolicy.BROWSER_COMPATIBILITY); client.getParams().setParameter("http.protocol.content-charset", encoding); client.getParams().setParameter("http.protocol.single-cookie-header", true); // logPostRequest(method); client.executeMethod(method); String responseStr = readInputStream(method.getResponseBodyAsStream(), encoding); method.releaseConnection(); System.out.println("responseStr:"+responseStr); if(responseStr.indexOf("HTTP-EQUIV=/"Refresh/"")!=-1){ String refreshPage =responseStr.substring(responseStr.indexOf("http:"), responseStr.indexOf("/">")); System.out.println("refreshPage:"+refreshPage); return doGet(refreshPage,"",encoding); } String welcomePage =""; if (method.getResponseHeader("Location") != null) { welcomePage = method.getResponseHeader("Location").getValue(); welcomePage = welcomePage.replaceAll("%3a", ":"); welcomePage = welcomePage.replaceAll("%3f", "?"); welcomePage = welcomePage.replaceAll("%26", "&"); if (method.getResponseHeader("Location").getValue().startsWith( "http")) { //System.out.println("welcomePage:"+welcomePage); return doGet(welcomePage,"", encoding); } else { //System.out.println("welcomePage2:"+"http://" + getResponseHost(method) + welcomePage); return doGet("http://" + getResponseHost(method) + welcomePage,"", encoding); } } else { //System.out.println("lastUrl:"+lastUrl); lastUrl = method.getURI().toString(); return responseStr; } } private String getResponseHost(PostMethod method) throws URIException { String url = method.getURI().toString(); return url.split("/")[2]; } protected String getJSRedirectLocation(String content) { String name = "window.location.replace(/""; int index = content.indexOf(name) + name.length(); content = content.substring(index); content = content.substring(0, content.indexOf("/"")); return content; } private String readInputStream(InputStream is) throws IOException { byte[] b = new byte[4096]; StringBuilder builder = new StringBuilder(); int bytesRead = 0; while (true) { bytesRead = is.read(b, 0, 4096); if (bytesRead == -1) { return builder.toString(); } builder.append(new String(b, 0, bytesRead, ENCODING)); } } private String readInputStream(InputStream is, String encoding) throws IOException{ StringBuffer temp = new StringBuffer(); BufferedReader buffer = new BufferedReader(new InputStreamReader(is,encoding)); for(String tempstr = ""; (tempstr = buffer.readLine()) != null;) temp = temp.append(tempstr+"/n"); buffer.close(); is.close(); String result = temp.toString().trim(); return result; } public String doGet(String url, String referer, String encoding) throws HttpException, IOException { GetMethod method = new GetMethod(url); setHeaders(method); method.setRequestHeader("Referer", referer); client.getParams().setCookiePolicy(CookiePolicy.BROWSER_COMPATIBILITY); client.getParams().setParameter("http.protocol.content-charset", encoding); client.getParams().setParameter("http.protocol.single-cookie-header", true); method.getParams().setParameter(HttpMethodParams.SO_TIMEOUT,15000); client.getHttpConnectionManager().getParams().setConnectionTimeout(15000); //logGetRequest(method); try{ client.executeMethod(method); String responseStr = readInputStream(method.getResponseBodyAsStream(), encoding); //logGetResponse(method, responseStr); //System.out.println("responseStr:"+responseStr); method.releaseConnection(); //lastUrl = method.getURI().toString(); return responseStr; }catch(Exception e){ return ""; } } }一般的网站数据url中会有一些数字,表示页数
用get方式获取对应url的源代码,其中i为page number,此处为占位符;StringUtil.getEncodingGB2312()为编码格式,这个要看网站的编码格式是什么,一般GB2312/UTF-8
String res = spider.doGet(String.format(url, i), "", StringUtil.getEncodingGB2312());获取网站源码之后,就是split、substring各种解析了。。。
下面是post方式,稍微复杂一点:
有些网站需要登录后,才能查看一些信息,所以我们需要模拟登陆
好,我们现在来举一个例子,只是一个例子啊,如果你是这个网站的负责人,不要来揍我,只是举一个例子。。。另外这也不是做广告(突然想起来)
http://www.cofeed.com/Login.asp 这是一个登陆界面
先注册一个,比如用户名,密码都是111111,然后用chrome打开 ,鼠标右击网页内任何一处,选择“审查元素”,
选择network,如下图,现在什么都没有

在登录界面输入用户名、密码之后,点击登录,发现已经有数据了
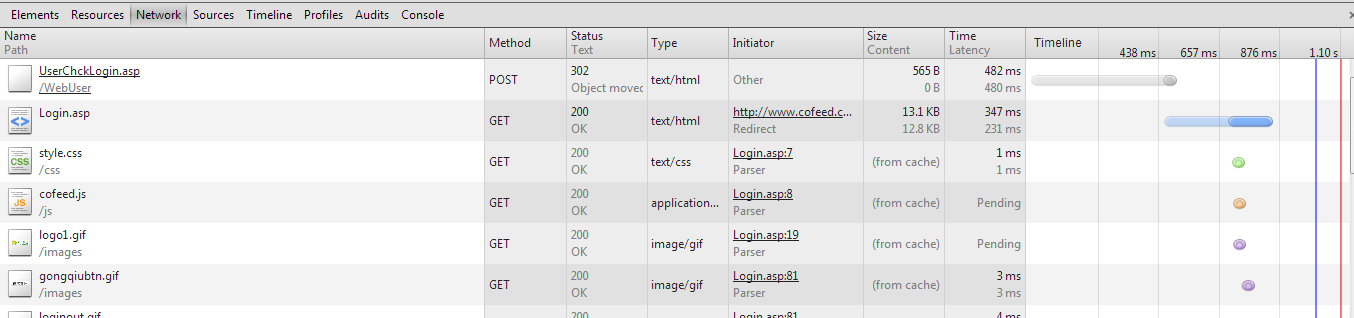
点击第一个

看到上面的Form Data了吗?表单提交,我们等会儿需要把数据都传过去
Cofeed_Name、coffeed_PWD、remember、act最好都传
接下来是post传参数的代码了 我这里少传了一个好像也没有问题,但是刚开始act没有传就没成功
BasicSpider spider = new BasicSpider(); spider.setClient(new HttpClient()); //form表单里面的都要传 NameValuePair params[] = { new NameValuePair("Cofeed_Name","111111"), new NameValuePair("cofeed_PWD","111111"), new NameValuePair("act", "LoginOk"), }; String content = spider .doPost("http://www.cofeed.com/WebUser/UserChckLogin.asp", params, "", StringUtil.getEncodingUTF_8());上面的content就跟刚才的get一样,是网页的源代码,不过我们需要的数据不是这个登陆界面的
再get一次就好
String res = spider.doGet(String.format(url, i), "", StringUtil.getEncodingUTF_8());接下来还是解析。。。
数据爬下来之后,可以保存到本地文件中,如txt文件,也可以直接插入到数据库。爬数据需要记录当前的page number,可能因为一些事情,暂时断掉,下次继续爬。另外有些网站可能有防爬机制,试试Thread.sleep(XXX),方法里面的时间可以是一个固定的,比如2秒(2000),也可以是随机的,比如4~6秒。要是不着急,可以定一个符合人类浏览网页的时间,这样就不会被发现,哈哈
