



1.添加hadoop组(专门用来进行hadoop测试)到系统用户:<!-- lang: java --> sudo addgroup hadoop2.在hadoop中添加hadoop用户:<!--
1.添加hadoop组(专门用来进行hadoop测试)到系统用户:
<!-- lang: java --> sudo addgroup hadoop2.在hadoop中添加hadoop用户:
<!-- lang: java -->sudo adduser --ingroup hadoop hadoop3.赋予hadoop管理员权限
<!-- lang: java -->sudo usermod -aG sudo hadoop( 如果不想新建用户,只在自己现有用户下搭建,上面三步可以省去直接进入第四步)4切换用户!!5.安装ssh远程登录协议:
<!-- lang: java -->sudo apt-get install openssh-server6.启动ssh
<!-- lang: java -->sudo /etc/init.d/ssh start7.免密码登录,并生成公钥与私钥:
<!-- lang: java -->ssh-keygen -t rsa -P ""第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥.8.现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容)
<!-- lang: java -->cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys9登录ssh
<!-- lang: java --> ssh localhost10退出
<!-- lang: java -->exit11再登录退出一次,之后登录就不用输入密码了。12安装java13安装hadoop,hadoop官网下载这里选择的是hadoop-1.2.1.tar.gz ,解压并放到你想放的地方
<!-- lang: java --> sudo mv /Downloads/hadoop-1.2.1.tar.gz /usr/local/hadoop14确保所有操作均在hadoop用户下
<!-- lang: java --> sudo chown -R hadoop:hadoop /usr/local/hadoop15配置hadoop-env.sh,所在目录:/usr/local/hadoop/conf,添加如下代码
<!-- lang: cpp -->export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386 (视你机器的java安装路径而定)export HADOOP_HOME=/usr/local/hadoopexport PATH=$PATH:/usr/local/hadoop/binexport HADOOP_HOME_WARN_SUPPRESS="TRUE" 16让环境变量配置生效
<!-- lang: java -->source /usr/local/hadoop/conf/hadoop-env.sh17单机配置成功:
<!-- lang: java -->hadoop version伪分布模式继续:18配置conf目录下三个文件:core-site.xml,hdfs-site.xml,mapred-site.xmlcore-site.xml:
<!-- lang: java --><configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration> hdfs-site.xml:
<!-- lang: java --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/hdfs/data</value> </property> </configuration> mapred-site.xml:
<!-- lang: java --><configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration> 19 在hadoop目录下新建几个目录:
<!-- lang: java --> ~/hadoop$ mkdir tmp ~/hadoop$ mkdir hdfs ~/hadoop$ mkdir hdfs/name ~/hadoop$ mkdir hdfs/data 20 修改data文件夹的权限:
<!-- lang: java -->sudo chmod g-w /usr/local/hadoop/hdfs/data21 让配置文件生效:
<!-- lang: java -->source /usr/local/hadoop/conf/hadoop-env.sh22.确认hadoop没有运行:
<!-- lang: java -->usr/local/hadoop bin/stop-all.sh23 格式化namenode
<!-- lang: java -->usr/local/hadoop bin/hadoop namenode -format 24运行
<!-- lang: java -->/usr/local/hadoop bin/start-all.sh25 jps如果出现下图表示成功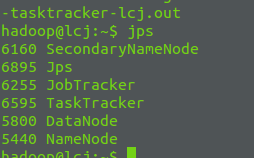
26测试程序:在伪分布模式下运行一下hadoop自带的例子WordCount来感受以下MapReduce过程:
这时注意程序是在文件系统dfs运行的,创建的文件也都基于文件系统:
首先在dfs中创建input目录
<!-- lang: java -->hadoop@lcj:/usr/local/hadoop$ bin/hadoop dfs -mkdir input 将conf中的文件拷贝到dfs中的input
<!-- lang: java --> hadoop@lcj:/usr/local/hadoop$ bin/hadoop dfs -copyFromLocal conf/* input 在伪分布式模式下运行WordCount
<!-- lang: java --> hadoop@lcj:/usr/local/hadoop$ bin/hadoop jar hadoop-examples-1.2.1.jar wordcount input output 显示输出结果
<!-- lang: java -->hadoop@lcj:/usr/local/hadoop$ bin/hadoop dfs -cat output/* 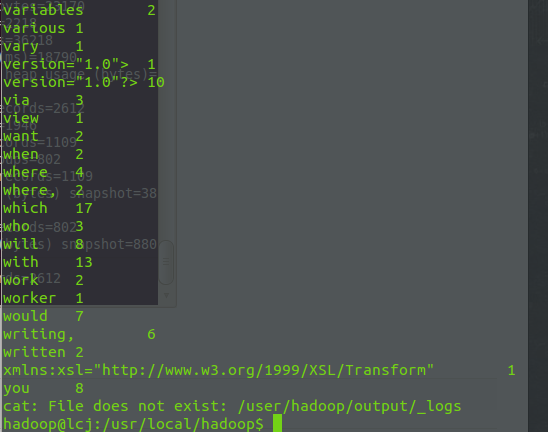
当Hadoop结束时,可以通过stop-all.sh脚本来关闭Hadoop的守护进程
<!-- lang: java -->hadoop@lcj:/usr/local/hadoop$ bin/stop-all.sh 本文主要参考的csdn狂奔的蜗牛,Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)链接,在此表示感谢,结合自己在安装时候出现的问题给以解决方法,加以总结。
